What is The Clinical SAS Programming
Introduction to Clinical SAS Programming
Clinical SAS Programming is a specialized area of SAS programming used in the pharmaceutical, biotechnology, and healthcare industries to support clinical trials. It involves processing, analyzing, and reporting clinical trial data in a structured and compliant manner. The primary purpose of Clinical SAS Programming is to transform raw clinical data into standardized datasets and analytical outputs that can be used to evaluate the safety and efficacy of drugs.

Unlike general data analysis, Clinical SAS Programming operates in a regulated environment where data accuracy, traceability, and consistency are critical. The outputs produced by Clinical SAS programmers directly contribute to regulatory submissions and clinical study reports that influence approval decisions by global health authorities.
What Clinical SAS Programming Really Means
Clinical SAS Programming means applying SAS tools and programming techniques specifically within the context of clinical research. It focuses on managing clinical trial data according to predefined standards and study protocols rather than performing ad-hoc analysis.
In practice, this involves:
Converting raw clinical trial data into standardized formats
Deriving variables based on clinical definitions
Preparing datasets for statistical analysis
Supporting generation of tables, listings, and figures
A Clinical SAS programmer must understand not only SAS syntax but also clinical concepts such as study visits, treatment periods, adverse events, laboratory results, and patient safety parameters. The role requires translating clinical requirements into reliable and reproducible SAS programs.
Many of these concepts are part of a structured Clinical SAS course curriculum designed for real-world clinical projects.
Clinical SAS Programming ensures that trial data is accurate, interpretable, and ready for analysis while maintaining full traceability from raw data to final results.
Why Clinical SAS Programming Is Different from General SAS
Clinical SAS Programming ensures that trial data is accurate, interpretable, and ready for analysis while maintaining full traceability from raw data to final results.
Clinical SAS Programming differs significantly from general SAS programming due to its regulatory and domain-specific nature. While general SAS is often used in business analytics or academic research, Clinical SAS is governed by strict industry standards and guidelines.
Key differences include:
Mandatory use of CDISC standards such as SDTM and ADaM
Strict documentation and validation requirements
Higher emphasis on data consistency and reproducibility
Regulatory review of datasets and programs

Clinical SAS is built on the Statistical Analysis System (SAS) framework, which is widely used across regulated industries
Role of Clinical SAS Programming in the Clinical Trials Lifecycle
Clinical SAS Programming plays a crucial role throughout the clinical trials lifecycle, from data collection to final submission. It supports multiple phases of a study by ensuring that data is properly prepared and analyzed at each stage.
During trial execution, Clinical SAS programmers assist in data cleaning and interim data reviews. As the study progresses, they create standardized datasets that enable statisticians to perform safety and efficacy analyses. In later stages, they support the preparation of tables, listings, and figures used in clinical study reports.
By maintaining consistency across datasets and analyses, Clinical SAS Programming ensures that study results accurately reflect the trial design and patient outcomes. This consistency is essential for making reliable clinical and regulatory decisions.
Importance of Clinical SAS Programming for Regulatory Submissions
Regulatory agencies require clinical trial data to be submitted in standardized and well-documented formats. Clinical SAS Programming ensures that datasets meet these requirements and are suitable for regulatory review.
Accurate SAS programming helps:
Demonstrate compliance with regulatory standards
Reduce data review queries from authorities
Improve transparency in data derivation and analysis
Support timely approval of new drugs and therapies
Because regulatory submissions are high-stakes and time-sensitive, the quality of Clinical SAS Programming directly impacts the success of a clinical trial submission. Well-structured programs and datasets build confidence in the validity and reliability of clinical trial results.Regulatory-ready datasets are often reviewed against guidance published by authorities such as the FDA and EMA.
Role of Clinical SAS in Clinical Trials & Pharma Industry
Clinical SAS Programming plays a central role in transforming clinical trial data into meaningful and compliant outputs used by pharmaceutical companies, biotechnology firms, and regulatory authorities. It acts as the technical bridge between raw data collection and final clinical evidence, ensuring that trial results are accurate, consistent, and reproducible.
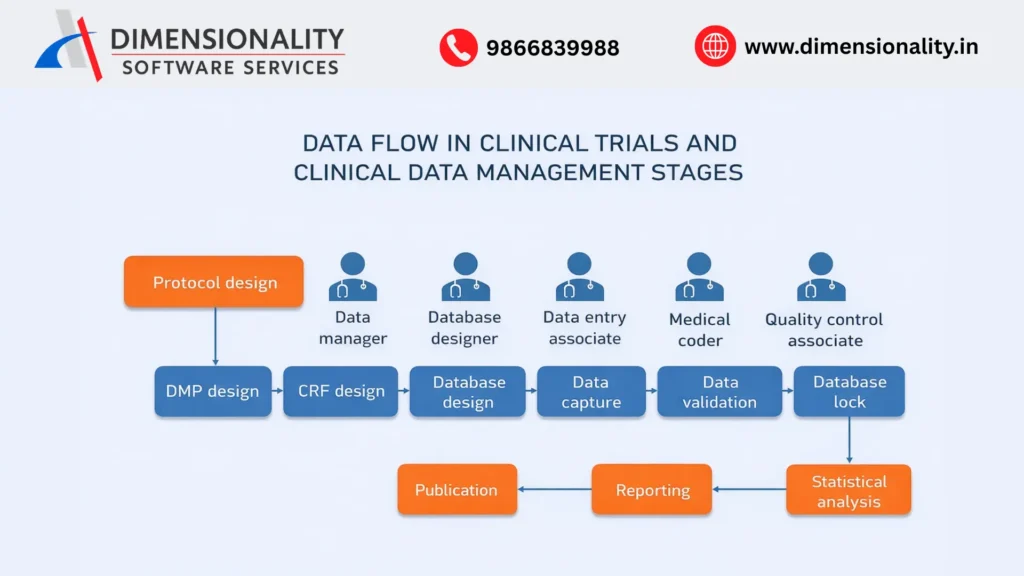
Where Clinical SAS Fits in the Clinical Data Flow
(Raw Data → SDTM → ADaM → TLFs)
In a clinical trial, data is collected from multiple sources such as electronic data capture systems, central laboratories, and external vendors. This raw data is not immediately suitable for analysis or regulatory review. Clinical SAS Programming ensures a structured flow of data through standardized stages.
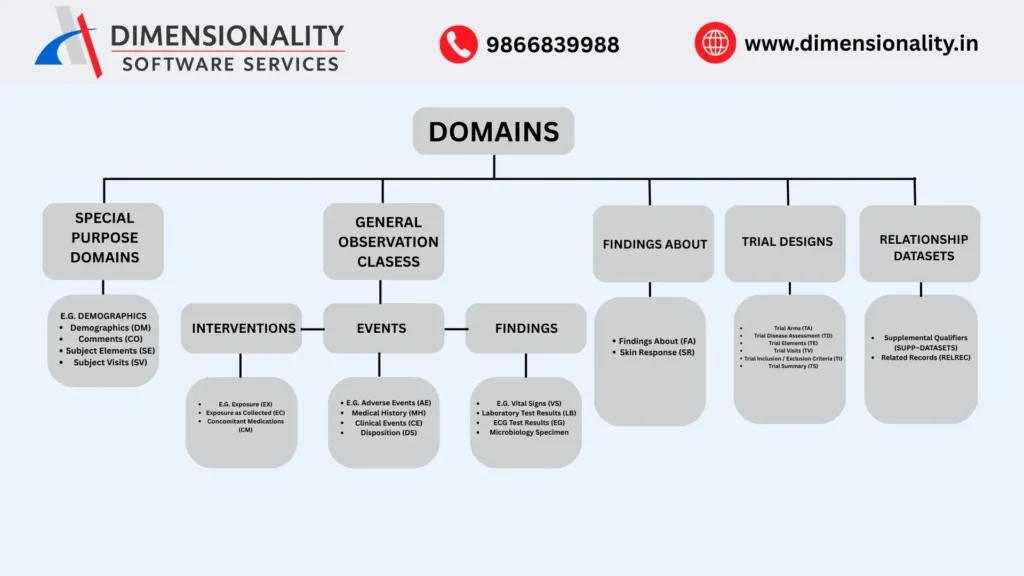
First, raw clinical data is converted into Study Data Tabulation Model (SDTM) datasets. These datasets organize collected information into standardized domains such as demographics, adverse events, laboratory results, and exposure data. Clinical SAS programmers derive and validate SDTM variables to ensure consistency across studies.
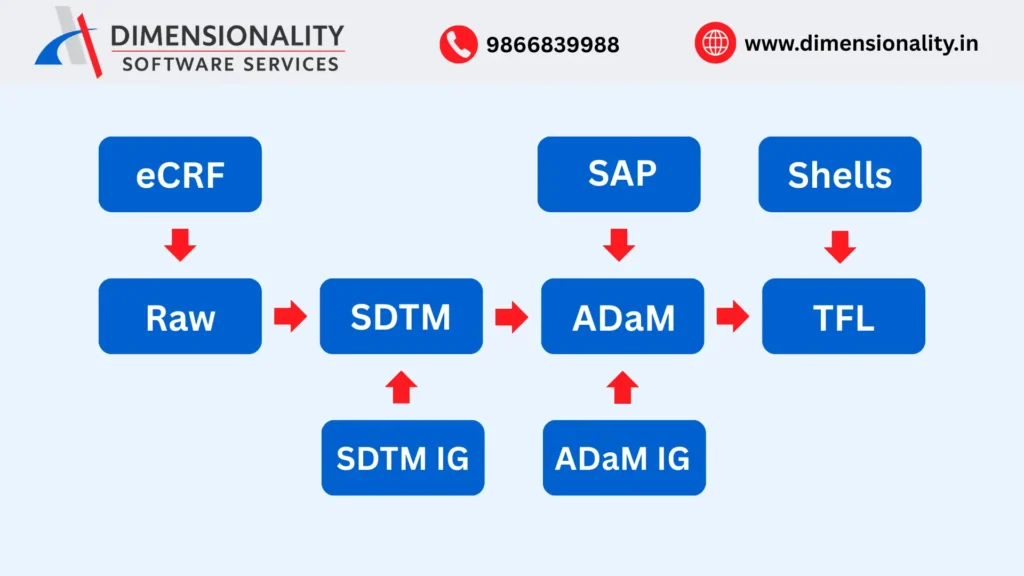
Next, SDTM datasets are transformed into Analysis Data Model (ADaM) datasets. ADaM datasets are specifically designed for statistical analysis and include derived variables such as analysis visit numbers, treatment flags, baseline values, and analysis windows. These datasets allow statisticians to perform accurate and reproducible analyses.
Finally, Tables, Listings, and Figures (TLFs) are generated using ADaM datasets. These outputs summarize safety and efficacy results and form a critical part of clinical study reports submitted to regulatory authorities.
Clinical SAS Programming ensures seamless data movement across these stages while maintaining traceability from raw data to final outputs.
CRO vs Sponsor Expectations in Clinical SAS Programming
The expectations of Clinical SAS Programming vary slightly between Contract Research Organizations (CROs) and pharmaceutical sponsors, but both demand high-quality and compliant deliverables.
CROs typically focus on:
Efficient dataset creation within tight timelines
Adherence to sponsor-specific standards and macros
Clear documentation and validation support
Smooth collaboration across multiple studies
Sponsors, on the other hand, emphasize:
Long-term data consistency across development programs
Reusability of SAS code and standards
Regulatory readiness and audit preparedness
Data integrity across submissions
Clinical SAS programmers must understand both perspectives and deliver solutions that meet operational efficiency while maintaining strategic consistency.
Why Accuracy and Reproducibility Matter in Clinical SAS
Accuracy and reproducibility are fundamental principles in Clinical SAS Programming because clinical trial results directly impact patient safety and regulatory decisions. Even small inconsistencies in data derivation can lead to incorrect analysis outcomes or regulatory review questions.
Accurate SAS programs ensure that derived variables correctly reflect the clinical intent defined in the study protocol and statistical analysis plan. Reproducible code allows results to be regenerated consistently across multiple runs, studies, and submissions.
Regulatory authorities expect that all results can be traced back to source data with clear and transparent logic. Clinical SAS Programming supports this requirement by maintaining structured derivations, validation checks, and consistent programming practices throughout the trial lifecycle.
Importance of Character & Date Handling in Clinical SAS
Character and date handling form the foundation of most derivations in Clinical SAS Programming. A large percentage of data issues encountered during clinical trial analysis can be traced back to incorrect text parsing or improper date calculations. Because clinical datasets often contain complex and inconsistent data formats, even minor errors in handling characters or dates can significantly affect downstream analysis.
Clinical SAS programmers must apply precise and consistent logic when working with character and date variables to ensure reliable and compliant datasets
Why Most Derivation Issues Come From Text Parsing
Text parsing is a common challenge in clinical trials because many clinical variables are captured as free-text or semi-structured values. Examples include visit labels, adverse event descriptions, protocol identifiers, and laboratory result strings. These values often vary across sites, studies, or data collection systems.
Incorrect parsing of text variables can lead to
Misclassification of visits
Inconsistent parameter codes
Errors in grouping or sorting data
Mismatches between collected and derived values
Clinical SAS programmers frequently rely on character functions to split, standardize, and clean text variables before they are used in SDTM or ADaM derivations. Accurate text handling ensures that derived variables correctly represent the clinical intent and align with study specifications.
Why Most Derivation Issues Come From Date Calculations
Date variables play a critical role in clinical trial analysis. Visit dates, treatment start and end dates, adverse event onset dates, and follow-up periods all depend on precise date calculations. Errors in date handling can occur due to missing dates, varying date formats, or incorrect assumptions about intervals.
Common issues related to date calculations include:
Incorrect visit window assignments
Misaligned baseline and post-baseline flags
Errors in treatment duration calculations
Inconsistent time-to-event results
Clinical SAS Programming requires careful handling of dates to ensure consistency across datasets and analyses. Proper date logic supports accurate interpretation of study timelines and patient outcomes.
Impact on VISIT and VISITNUM
VISIT and VISITNUM variables are central to clinical data analysis and reporting. They define the structure of patient visits and determine how data is ordered and summarized. Errors in character parsing or date derivation can cause incorrect visit labeling or sequencing.
Incorrect VISIT or VISITNUM values can lead to:
Improper data sorting
Inaccurate summary statistics
Misinterpretation of treatment effects over time
Accurate character and date handling ensures that visit-related variables are derived consistently and reflect the true study schedule.
Impact on Analysis Windows
Analysis windows define the time frames used to include or exclude data for statistical analysis. These windows are often based on visit dates or treatment milestones. Incorrect date calculations can shift data into the wrong analysis window, affecting baseline definitions and endpoint evaluations.
Clinical SAS programmers must ensure that analysis windows are derived using consistent and well-documented date logic. This helps statisticians perform valid analyses and supports transparent regulatory review.
Impact on Safety Reporting
Safety reporting relies heavily on accurate date and text handling. Adverse event timing, severity classification, and treatment exposure all depend on precise derivations. Errors in character or date variables can lead to incorrect safety summaries or delayed identification of potential risks.
Reliable character and date handling supports accurate safety evaluations and ensures that clinical trial results reflect true patient experiences.
SAS SCAN Function in Clinical SAS Programming
The SAS SCAN function is one of the most frequently used character functions in Clinical SAS Programming. It plays a critical role in extracting meaningful components from character strings that commonly appear in clinical trial data. Visit labels, subject identifiers, adverse event terms, and laboratory result descriptions often contain multiple pieces of information combined into a single text value. The SCAN function allows programmers to separate these values accurately and consistently.
Because clinical datasets rarely follow a single fixed text pattern, SCAN provides the flexibility required to handle real-world clinical data variations.
What Is SCAN in the Clinical Context
In the clinical context, the SCAN function is used to extract specific words or tokens from character variables based on defined delimiters. Rather than relying on fixed character positions, SCAN identifies logical segments within a string, making it suitable for data collected from multiple sites and vendors.
Clinical trial data frequently includes labels such as visit names, protocol identifiers, or descriptive terms that are separated by spaces, hyphens, or other symbols. SCAN enables programmers to isolate relevant components without making assumptions about string length or format.
This flexibility makes SCAN particularly valuable for standardizing raw text fields before they are used in SDTM and ADaM datasets.
SCAN Syntax Explained for Clinical Use
The SCAN function follows a simple syntax that is well-suited for clinical data manipulation. It requires a character string, the position of the word to extract, and optionally, the delimiters used to separate values.
In clinical programming, SCAN is commonly used with:
Explicit delimiters to handle inconsistent text formats
Positive indexing to extract values from the beginning of a string
Negative indexing to extract values from the end of a string
By defining delimiters clearly, Clinical SAS programmers can ensure that extracted values remain consistent across patients, visits, and studies. This consistency is essential when deriving variables such as visit numbers, test codes, or subject identifiers.
Why SCAN Is Preferred Over SUBSTR in Clinical Trials
While both SCAN and SUBSTR can be used to extract portions of a character string, SCAN is generally preferred in Clinical SAS Programming due to its flexibility and reliability. SUBSTR depends on fixed character positions, which can lead to errors when text formats vary across records.
Clinical trial data often contains:
Variable-length strings
Inconsistent spacing or delimiters
Additional descriptors added during data collection
SCAN handles these variations more effectively by focusing on logical word boundaries rather than character positions. This reduces the risk of incorrect derivations and improves the robustness of clinical datasets.
Because regulatory submissions require reproducible and auditable results, SCAN is often the safer choice for extracting text-based values in clinical trials.
Real-World Applications of SCAN in Clinical Datasets
In real clinical studies, character variables rarely appear in clean or uniform formats. Data collected from multiple sites, vendors, and regions often contains descriptive text that must be parsed and standardized before it can be used for analysis. The SAS SCAN function is widely used in Clinical SAS Programming to handle these real-world challenges efficiently and reliably.
This section highlights how SCAN is applied across common clinical datasets to support accurate derivations and regulatory-compliant outputs.
Visit Label Parsing
Visit labels in clinical trials often combine multiple pieces of information into a single text value. Examples include visit number, study week, or visit description. These labels are used to define visit structure and are critical for sorting, analysis, and reporting.
Clinical SAS programmers use SCAN to extract meaningful components from visit labels without relying on fixed positions. This approach allows visit-related variables to remain consistent even when label formats vary across studies or data sources.
Accurate visit label parsing ensures that visit-based variables such as VISIT and VISITNUM correctly represent the study schedule and support reliable statistical analysis.
Adverse Event Term Standardization
Adverse event descriptions may include additional qualifiers, severity indicators, or site-specific notes. These variations can complicate grouping and summarization during safety analysis.
The SCAN function helps isolate the primary adverse event term from additional descriptors. By extracting standardized components, Clinical SAS programmers can ensure that adverse events are categorized consistently across patients and studies.
Standardized adverse event terms improve the quality of safety summaries and reduce discrepancies during medical review and regulatory submission.
Lab Result Value and Unit Separation
Laboratory result fields often contain both numeric values and measurement units in a single character variable. Before analysis, these components must be separated and stored in appropriate variables.
Using SCAN, programmers can extract the numeric result and its corresponding unit based on defined delimiters. This approach supports accurate numerical analysis while preserving unit information for reporting and validation.
Proper separation of lab values and units is essential for deriving baseline values, identifying outliers, and ensuring consistency across laboratory datasets.
Subject and Protocol Identifier Extraction
Subject IDs and protocol identifiers often follow structured naming conventions that include multiple segments separated by delimiters. These identifiers may contain site numbers, subject numbers, or protocol codes within a single string.
The SCAN function enables Clinical SAS programmers to extract specific components from these identifiers, such as subject numbers or site codes, without assuming fixed formats. This flexibility is especially useful when working with multi-center or multi-protocol studies.
Accurate identifier extraction supports proper data merging, subject tracking, and cross-domain consistency.
SDTM and ADaM Variable Derivations
SCAN is extensively used in deriving SDTM and ADaM variables that rely on character manipulation. Variables such as visit labels, parameter codes, test codes, and descriptive flags often require parsing of text values.
By using SCAN, programmers can derive standardized variables that align with CDISC guidelines and study specifications. This supports consistency across datasets and improves traceability from raw data to analysis-ready outputs.
Effective use of SCAN in SDTM and ADaM derivations reduces the risk of derivation errors and supports smooth regulatory review.
Advanced SCAN Techniques Used by Senior Clinical SAS Programmers
Senior Clinical SAS programmers go beyond basic usage of the SCAN function to handle complex, inconsistent, and real-world clinical data scenarios. These advanced techniques help ensure robustness, clarity, and regulatory readiness of derived variables, especially in studies involving multiple sites, vendors, and regions.
Using SCAN Modifiers (b, q, m, s) in Real Clinical Data
SCAN modifiers provide additional control over how character strings are parsed, which is particularly useful in clinical datasets where text formats are not always consistent.
The b modifier is used to treat multiple consecutive delimiters as a single delimiter. This is helpful when data contains irregular spacing between words, which is common in manually entered text fields.
The q modifier allows SCAN to ignore delimiters enclosed within quotation marks. This is useful when working with text that includes quoted descriptions or comments.
The m modifier allows missing words to be counted. This helps maintain positional consistency when some segments of a string are missing.
The s modifier strips leading and trailing delimiters, ensuring cleaner extracted values.
Using these modifiers correctly helps senior programmers handle complex character strings without introducing fragile or hard-coded logic.
Handling Inconsistent Delimiters Across Clinical Data Sources
Clinical trial data often originates from different systems and vendors, each using its own formatting conventions. As a result, delimiters such as spaces, hyphens, slashes, or commas may be used inconsistently within the same variable.
Senior Clinical SAS programmers explicitly define delimiters in the SCAN function rather than relying on default behavior. This practice ensures consistent parsing across records and studies, even when text formats vary.
By anticipating delimiter inconsistencies, programmers can write more resilient code that performs reliably across diverse datasets.
Combining SCAN with STRIP, UPCASE, and COMPRESS
In clinical programming, SCAN is rarely used in isolation. It is often combined with other character functions to improve data consistency and reliability.
STRIP is used to remove leading and trailing spaces from extracted values.
UPCASE ensures uniform capitalization, which is essential for consistent grouping and comparison.
COMPRESS helps remove unwanted characters such as special symbols or extra spaces.
Combining these functions with SCAN allows programmers to produce standardized and clean character variables suitable for SDTM and ADaM datasets.
Writing Validation-Friendly SCAN Logic
Validation-friendly coding is a key expectation in Clinical SAS Programming. Senior programmers write SCAN logic that is easy to review, test, and explain during validation or regulatory audits.
This involves:
Using clear and descriptive variable names
Avoiding overly complex nested logic
Documenting assumptions and derivation steps
Ensuring consistent behavior across edge case
Validation-friendly SCAN logic improves transparency, reduces rework, and builds confidence in derived datasets.
Best Practices and Common Mistakes with SCAN in Clinical SAS
Using the SCAN function correctly is not only a technical requirement but also a regulatory expectation in Clinical SAS Programming. Regulatory reviewers and internal quality teams closely examine how character derivations are implemented, especially when they influence key variables used in analysis and reporting. Following best practices helps ensure that SCAN-based derivations are clear, reliable, and audit-ready.
Audit Expectations When Using SCAN
From an audit perspective, SCAN logic must be transparent and reproducible. Auditors expect that derived character variables can be easily traced back to their source data and that the logic used is consistent with the study protocol and specifications.
Key audit expectations include:
Clear identification of source variables
Explicit delimiter definitions
Consistent behavior across all records
Logical handling of missing or unexpected values
SCAN-based derivations should produce the same results every time the program is executed, ensuring reproducibility across validation and regulatory review cycles.
Writing Reviewer-Friendly SCAN Logic
Reviewer-friendly code is easy to understand, maintain, and validate. In Clinical SAS Programming, reviewers often include validation programmers, statisticians, and regulatory reviewers who may not be familiar with every detail of the original program.
To make SCAN logic reviewer-friendly:
Keep derivations simple and well-structured
Avoid deeply nested function calls
Use meaningful variable names that reflect clinical intent
Include concise comments explaining the purpose of each derivation
Clear SCAN logic reduces review time, minimizes clarification requests, and supports smooth regulatory submissions.
Common Mistakes to Avoid in Regulatory Code
In regulatory Clinical SAS Programming, SCAN-based derivations can become unreliable if common mistakes are not consciously avoided. One frequent issue is relying on fixed word positions while assuming that input text will always follow the same structure. In real clinical trial data, character values often vary due to differences in site-level data entry, spelling variations, data capture systems, or formatting changes across vendors and studies. Making rigid assumptions about text structure can therefore lead to incorrect or inconsistent derived values.
Another common mistake is using default delimiters in the SCAN function without first validating the actual structure of the source data. Clinical datasets may contain spaces, hyphens, slashes, commas, or mixed delimiters within the same variable. If delimiters are not explicitly defined based on observed data patterns, SCAN may return incorrect, partial, or missing values, weakening the reliability of regulatory datasets.
Ignoring missing, partial, or malformed values is also a significant issue in regulatory programming. Clinical trial data frequently contains incomplete or unexpected text due to protocol deviations, data entry errors, or upstream system limitations. SCAN logic must explicitly account for such scenarios to ensure consistent behavior across all records and to prevent downstream analysis discrepancies.

Failure to standardize extracted character values—such as not removing extra spaces, not normalizing case, or not handling special characters—can further introduce inconsistencies in grouping, sorting, and reporting. In addition, writing overly complex parsing logic without clear documentation makes programs difficult to review, validate, and defend during audits or regulatory inspections.
Another risk arises when SCAN is used in situations where a lookup table or controlled mapping approach would be more appropriate. Selecting the correct method for each derivation is essential to maintain clarity, traceability, and long-term maintainability of regulatory code.
Avoiding these mistakes helps ensure that SCAN-based derivations remain robust, traceable, validation-friendly, and fully aligned with clinical trial requirements and regulatory standards.
SAS INTNX Function in Clinical SAS Programming
Date handling is one of the most critical and high-risk areas in Clinical SAS Programming. Clinical trial analyses depend heavily on accurate calculation of visit dates, treatment durations, follow-up periods, and analysis windows. Even a small error in date logic can lead to incorrect patient classification, flawed analysis results, or regulatory queries. The SAS INTNX function is widely used to manage these risks by providing a consistent and reliable way to perform date-based calculations.
Why Date Calculations Are High-Risk in Clinical Trials
Clinical trials are structured around timelines. Study visits, dosing schedules, safety assessments, and endpoint evaluations all rely on precise date calculations. Any inconsistency in how dates are derived can affect key trial outcomes.
Date calculations become high-risk due to:
Incomplete or partially missing dates
Variations in visit schedules across subjects
Differences in month lengths and leap years
Protocol-defined windows that must be applied consistently
Incorrect date logic can result in misaligned visit windows, incorrect baseline flags, or inaccurate treatment exposure calculations. These issues often surface during validation or regulatory review, making date handling a critical focus area for Clinical SAS programmers.
INTNX Function Overview in Clinical SAS
The INTNX function is a core SAS date function used to increment a date, datetime, or time value by a specified interval. In Clinical SAS Programming, INTNX is primarily used to derive clinically meaningful dates based on protocol definitions rather than performing manual date arithmetic.
INTNX supports increments by common clinical intervals such as days, weeks, months, quarters, and years. It also provides alignment options that allow programmers to control where the derived date falls within the specified interval. This flexibility is essential when deriving visit dates, follow-up periods, and analysis windows.
By using INTNX, Clinical SAS programmers can ensure consistent and reproducible date derivations across patients, visits, and studies. This consistency helps maintain alignment with study protocols and supports accurate statistical analysis and regulatory submissions.
INTNX Syntax and Alignment Explained for Clinical Trials
Understanding the syntax and alignment options of the INTNX function is essential for accurate date derivations in Clinical SAS Programming. Clinical trials follow strict protocol-defined schedules, and date calculations must reflect these schedules precisely. INTNX provides the structure needed to implement consistent and reproducible date logic across studies.
Interval Types Commonly Used in Clinical Trials
Clinical trials rely on specific time intervals to define visits, treatment periods, and follow-up assessments. The most commonly used interval types in INTNX reflect how clinical events are scheduled and evaluated.
Typical interval types include:
DAY for short-term events such as dosing days or safety follow-ups
WEEK for scheduled visits and treatment cycles
MONTH for periodic assessments such as laboratory tests
QTR for longer-term evaluations
YEAR for annual follow-up or long-term safety studies
Using standardized interval types ensures that derived dates remain consistent with the clinical protocol and study design.
Understanding INTNX Alignment Options in Clinical Context
INTNX alignment controls where the derived date falls within the specified interval. Alignment is particularly important in clinical trials where visit windows and assessment periods are strictly defined.
Beginning (B) aligns the result to the first day of the interval. This is often used for defining the start of a visit window or treatment period.
Middle (M) places the derived date at the midpoint of the interval. This may be used for mid-cycle assessments.
End (E) aligns the result to the last day of the interval. This is commonly used for end-of-month or end-of-period derivations.
SAME retains the same relative position as the start date and is frequently used when exact date alignment is required.
Choosing the correct alignment ensures that derived dates accurately reflect protocol-defined expectations and avoid unintended shifts in analysis windows.
INTNX helps ensure that event-related dates are derived consistently and aligned with protocol definitions. This consistency supports accurate calculation of event times and improves the reliability of survival and risk analyses.
Proper use of INTNX in time-to-event preparation strengthens the integrity of statistical conclusions drawn from clinical studies.
reproducibility, and strengthens the reliability of trial results.
Protocol-driven use of INTNX helps ensure that date derivations remain defensible during validation and regulatory review.
Applying Protocol-Driven Date Logic Using INTNX
Clinical SAS Programming requires that all date derivations align with the study protocol and statistical analysis plan. INTNX supports protocol-driven logic by allowing programmers to apply consistent date increments and alignments across all subjects.
By referencing protocol definitions when selecting interval types and alignment options, programmers can derive visit dates, follow-up periods, and analysis windows that accurately represent the clinical intent of the study. This approach reduces ambiguity, supports
Real-World Applications of INTNX in Clinical Studies
The INTNX function is extensively used in Clinical SAS Programming to derive dates that define study timelines, treatment periods, and analysis windows. In clinical studies, these derived dates must strictly follow protocol definitions and remain consistent across all subjects. INTNX provides a reliable way to implement this logic without relying on manual or error-prone date calculations.
Visit Date Derivation
Visit dates are central to clinical trial analysis. While raw data may contain visit labels or scheduled dates, actual visit dates often need to be derived based on protocol-defined intervals.
Clinical SAS programmers use INTNX to calculate visit dates relative to reference dates such as randomization or first dose dates. This ensures that visit timing remains consistent across subjects, even when visits occur earlier or later than planned.
Accurate visit date derivation supports correct visit sequencing, analysis window assignment, and interpretation of treatment effects over time.
Follow-Up Period Derivation
Follow-up periods define the timeframe during which patients are monitored after treatment completion or study milestones. These periods are critical for safety assessments and long-term outcome evaluation.
INTNX allows programmers to derive follow-up start and end dates by incrementing key reference dates using protocol-defined intervals. This approach ensures uniform follow-up calculations across the study population.
Consistent follow-up derivations support reliable safety summaries and reduce discrepancies during data review and regulatory evaluation.
End-of-Treatment Date Calculation
The end-of-treatment date marks a key transition point in a clinical trial. It often determines the start of follow-up, baseline for subsequent analyses, or inclusion in specific safety populations.
Using INTNX, Clinical SAS programmers can derive end-of-treatment dates based on treatment start dates and defined dosing durations. This ensures that treatment exposure is calculated accurately and consistently.
Correct end-of-treatment derivations are essential for evaluating treatment duration, compliance, and safety outcomes.
Analysis Window Creation
Analysis windows define the periods during which data is included in statistical analyses. These windows are often based on visit dates, treatment milestones, or protocol-defined offsets.
INTNX supports precise window creation by allowing programmers to increment dates forward or backward relative to reference points. This ensures that baseline and post-baseline data are correctly classified.
Accurate analysis window derivation is critical for valid efficacy and safety analyses and supports transparent regulatory review.
Time-to-Event Preparation
Time-to-event analyses rely on accurate measurement of the time between key clinical events, such as treatment initiation and occurrence of an adverse outcome. Date derivations form the foundation of these analyses.
Advanced INTNX Usage in SDTM and ADaM
In standardized clinical datasets such as SDTM and ADaM, date derivations must be consistent, traceable, and aligned with protocol and analysis requirements. Advanced use of the INTNX function allows Clinical SAS programmers to handle complex date scenarios while maintaining regulatory compliance and long-term maintainability of code.
Implementing Month-End Logic in Clinical Datasets
Month-end logic is commonly required in clinical studies for laboratory assessments, exposure summaries, and periodic evaluations. Because months vary in length, manual date calculations can easily introduce inconsistencies.
INTNX provides a reliable approach to derive end-of-month dates by aligning results to the end of the specified interval. This ensures that derived dates accurately reflect calendar boundaries regardless of month length or leap years.
Using standardized month-end logic supports consistency across patients and simplifies validation and regulatory review.
Ensuring Consistent Derivations Across Multiple Studies
Pharmaceutical development programs often involve multiple studies conducted over several years. Consistency in date derivations across these studies is essential for integrated analyses and regulatory submissions.
By using INTNX with standardized intervals and alignment rules, Clinical SAS programmers can apply uniform date logic across studies. This reduces variability, improves comparability, and supports pooled analyses.
Consistent use of INTNX also enables code reusability, which is particularly valuable in long-term clinical development programs.
Avoiding Hard-Coded Date Calculations
Hard-coded date arithmetic, such as adding fixed numbers of days, can lead to errors and reduce code flexibility. These approaches often fail to account for varying month lengths, leap years, or protocol-specific definitions.
INTNX eliminates the need for hard-coded date math by allowing programmers to define date increments in logical and clinically meaningful units. This results in clearer, more robust code that adapts easily to protocol changes.
Avoiding hard-coded date calculations improves code readability, reduces maintenance effort, and enhances regulatory defensibility.
INTNX vs INTCK in Clinical SAS Programming
INTNX and INTCK are both SAS date functions, but they serve different purposes in Clinical SAS Programming. Understanding when to use each function is essential for accurate date derivations and analysis. Misuse of these functions is a common source of confusion and can lead to incorrect clinical results.
When to Increment Dates vs When to Count Intervals
The INTNX function is used to increment a date by a specified interval.A. It provides a solution to the query, “What is the date after adding a defined time period?” Because of this, INTNX can be used to determine visit dates, follow-up times, treatment completion dates, and analysis windows.
In clinical trials, INTNX is typically applied when defining or deriving dates, while INTCK is used when measuring time intervals for analysis.
Clarifying Common Confusion in Clinical Use
A common mistake in clinical programming is using INTCK when a derived date is required or using INTNX when a duration is needed. This confusion often arises because both functions involve intervals such as days, weeks, or months.
Using INTCK to derive dates can result in incorrect values because it counts interval boundaries rather than incrementing dates. Similarly, using INTNX to measure duration can lead to misinterpretation of time-based outcomes.
Clear understanding of the distinct roles of INTNX and INTCK helps Clinical SAS programmers apply the correct function in each scenario. This clarity reduces derivation errors, improves analysis accuracy, and supports reliable regulatory submissions.
Using SCAN and INTNX Together in Clinical SAS Programming
In real clinical studies, character and date derivations are rarely independent. Visit labels, visit numbers, and visit dates are often interconnected, and deriving them correctly requires a combination of character parsing and date calculation logic. Using SCAN and INTNX together allows Clinical SAS programmers to create consistent, protocol-aligned derivations that accurately reflect the clinical study design.
This combined approach supports end-to-end derivation workflows that are both robust and regulatory-ready.
From Visit Label to Visit Date: An Integrated Derivation Flow
Visit labels often contain descriptive information such as visit number, study week, or visit name. These labels are typically stored as character variables and may vary in format across subjects or studies. SCAN is used to extract meaningful components from these labels, such as visit numbers or week identifiers.
Once visit-related information is extracted, INTNX is applied to derive corresponding visit dates based on protocol-defined reference dates. For example, a visit number or week extracted from a label can be used to calculate the expected visit date relative to randomization or treatment start.
By combining SCAN for character extraction and INTNX for date incrementing, Clinical SAS programmers ensure that visit labels, visit numbers, and visit dates remain logically aligned.
End-to-End Derivation Thinking in Clinical SAS
End-to-end derivation thinking involves viewing character and date variables as part of a single derivation chain rather than isolated steps. Senior Clinical SAS programmers design derivations that start from raw data and flow consistently through SDTM and ADaM datasets.
Using SCAN and INTNX together supports:
Consistent visit sequencing
Accurate analysis window assignment
Clear traceability from raw data to analysis-ready variable
This integrated approach reduces the risk of misalignment between character labels and date values, strengthens dataset consistency, and improves regulatory confidence in clinical trial results.
FAQs on Clinical SAS Programming
Career and Industry Perspective in Clinical SAS Programming
Clinical SAS Programming is not only a technical role but also a career that demands domain understanding, precision, and accountability. Employers in the pharmaceutical and clinical research industries evaluate programmers not just on their ability to write code, but on how well they understand clinical data, standards, and regulatory expectations. Mastery of foundational concepts and commonly used functions plays a significant role in long-term career growth.
Why Functions Like SCAN and INTNX Matter in Interviews
In Clinical SAS interviews, questions often focus on real-world problem-solving rather than theoretical knowledge. Functions such as SCAN and INTNX are frequently discussed because they are used daily in clinical projects.
Interviewers assess:
How candidates handle inconsistent character data
How they derive visit dates and analysis windows
Whether they understand the impact of derivation logic on study outcomes
A clear explanation of how SCAN and INTNX are applied in clinical datasets demonstrates practical experience and an understanding of industry workflows.
Expectations from CROs and Pharmaceutical Companies
CROs and pharmaceutical sponsors expect Clinical SAS programmers to deliver accurate, validated, and review-ready outputs. This includes the ability to follow standards, interpret specifications, and implement protocol-driven logic consistently.
Key expectations include:
Strong understanding of SDTM and ADaM datasets
Ability to write clean, reproducible SAS code
Awareness of regulatory and audit requirements
Effective collaboration with data management and statistics teams
Meeting these expectations requires a solid grasp of core SAS functions and clinical concepts.
How Mastering the Basics Builds Long-Term Authority
In Clinical SAS Programming, authority is built by consistently applying basic principles correctly across studies. Mastery of fundamental functions such as SCAN and INTNX allows programmers to handle complex scenarios with confidence and clarity.
Strong foundational skills lead to:
Fewer derivation errors
Faster validation cycles
Greater trust from reviewers and stakeholders
Over time, this reliability positions programmers as subject-matter experts and opens opportunities for senior roles and leadership positions within clinical research teams.
Conclusion
Clinical SAS Programming sits at the intersection of accuracy, compliance, and career growth. Every dataset derived, every variable created, and every date calculated contributes directly to how clinical trial results are interpreted and reviewed. In a regulated environment, accuracy is not optional—it is a responsibility. Correct character handling and precise date derivations ensure that clinical data reflects true patient outcomes and study intent.
Compliance is equally critical. Regulatory agencies expect transparent, reproducible, and well-documented datasets that adhere to established standards. Clinical SAS Programming provides the structure and discipline required to meet these expectations, reducing review queries and supporting successful regulatory submissions. Strong programming practices build trust in the data and confidence in the conclusions drawn from it.
From a career perspective, mastering the fundamentals of Clinical SAS Programming creates a strong professional foundation. Programmers who consistently apply accurate logic, follow standards, and understand clinical workflows develop credibility within CROs and pharmaceutical organizations. Over time, this expertise translates into greater responsibility, career stability, and opportunities for growth.
Ultimately, Clinical SAS Programming is more than a technical skill—it is a critical function that supports patient safety, regulatory decision-making, and the advancement of new therapies. By focusing on accuracy, compliance, and strong fundamentals, Clinical SAS programmers play a vital role in the success of clinical research and their own long-term careers.